
I've spent some time dissing the Rider Over Bull (ROB) stat as a useful measurable in the past. But, lets look at how to MAKE it convey something useful, or at least explain its weaknesses.
There are a few problems with the data itself pertaining to ROB numbers that cause them end up being misleading if you are using it to compare one rider to another.
It is subjective by nature. For each single ride the ROB is the result of input from 2 to 4 judges who probably aren't thinking exactly the same way. All of them think about whether the rider should be over, even with or under the bull, but how much can vary with individual judges. So the grain of salt is, each rider's scores are affected greatly by the judges he's been seen by most often.
There is nothing to be done about the subjectivity part of it. It's baked in. But by thinking about what exactly we hope to discover by looking at ROB we can mitigate some of the problem with outliers.
A good starting point would be to define our goal. It seems to me the most relevant questions we can probably answer with ROB are - which riders tend to get the maximum scores out of their bulls, or which riders do the judges tend to mark better. Ultimately, which riders tend to look better on their bulls or tend to be more "in control" of their bulls. This brings up another issue with the data itself, which may be hard to understand. For each qualified ride, the judges score the rider and the bull and a total score is reached. We can't compare different riders on the same exact bull and trip, but we can approximate it by looking at a lot of outs by a lot of riders competing on bulls that are in the same performance range. Obviously some scores will be higher than others, but the difference in two riders on almost the same bull and trip will not all be reflected by ROB. Some of the difference goes to the bull too. This is provable by looking at data as well. If Sandro Batista and Chase Outlaw were to ride identical bulls, the bull would score slightly higher with Chase most of the time, and this becomes visible when you look at the difference between smaller riders and larger ones on thousands of bulls. This is no fault of the riders or really even the judges, it's just nature than the same bull tends to look more impressive with a smaller rider. There are always exceptions to this general rule.
Given the above, we can expect smaller built riders to dominate ROB and just higher overall score potential most of the time, and they do. This is part of my original beef with the usefulness of ROB. I would expect that you can eyeball it based on the rider and get pretty close without doing hours of math and testing.
Lets look at some data and consider what ROB might have to tell us. Consider the following table.
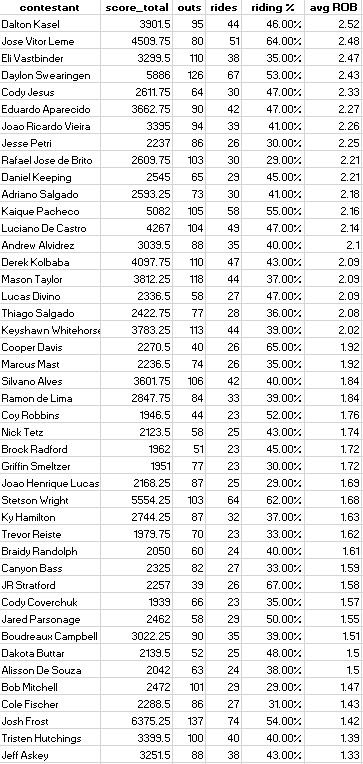
This is an overview of the performance metrics of a bunch of riders based on the past 365 days and ignores outs where the bull scored under 40 points. On low scoring bulls, ROB is less consistent, and really less relevant if we are mostly concerned with rider performance.
Note that there's an exception to the rider size trend with a larger rider - Eli Vastbinder - right at the top in ROB. This brings up another caveat related to ROB and rider size. Presumably, ROB measures how "in control" riders tend to be. But, the opposite of "in control" is "out of control" and the usual outcome of a ride where the rider experiences loss of control is a buckoff. For larger riders, the tolerance range for loss of control is narrower than it is for smaller riders due to the laws of physics. In this case the cluster of smaller guys with similar ROB did get more of their bulls ridden.
So this data set does accurately measure ROB to the extent that it can be. The data also excludes the 2022 NFR because the actual bull scores for that event are not available (yet). Another way to look at this is to restrict the data even further by only including bulls that scored 43-44 points or more, which gives different results.
But here's the bigger picture. Whether you are trying to evaluate riders trying to make a Team better, or predict the next world champion, or for most any other reason, the other numbers in this data set are a bigger help to you than ROB. There's another measurable not shown here that would be more helpful than ROB - average ride score. If one rider has an average ride score higher than another, it's mostly because he's staying on better bulls more often. And "staying on" is directly related to "in control".
There are at least a couple of ways ROB may be useful in other contexts. If you look at individual outs, then ROB is really relevant to that particular out. So it should be possible to look at all a rider's outs with ROBs and get a clear picture of what type of bull is ideal for that rider and what kinds of bulls are not. You could also look at the average ROB for a lot of bulls and learn which ones are best at making riders uncomfortable. We'll try to dig into this next time.


